Rectified Linear Unit(ReLU) function is one of the activation functions used massively in neural networks. ReLU function and its variants have gained massive popularity and use in the pools of other activation functions like sigmoid, tanh, etc because of its advantages over other activation functions which we would discuss in another separate article.
ReLU function is defined as:
$$ ReLU(x)=\begin{cases} x\quad if\quad x>0 \\ 0\quad if\quad x\le 0 \end{cases} $$
Its graph is drawn as:
Sigmoid function in its structure has curved shape but ReLU function lacks the curved structure that sigmoid function has. So, it is normal to wonder and question ReLU's implementation on how does it achieve non-linearity. I will try here to give intuition on it.
The first intuition you can get is by looking at the shape of ReLU function above. Linear function forms the lines, straight lines. But the ReLU function is not straight line rather a piecewise function that looks broken at the value of x equal to 0. That gives little intuition on its non-linearity.
Let's delve into it further now. Suppose there is the data that has input and output distribution which can be modeled with absolute value function. We employ neural network into it and then use ReLU as activation. The training of the model selects the biases and variables in such a way that the neural network mimics absolute value function.
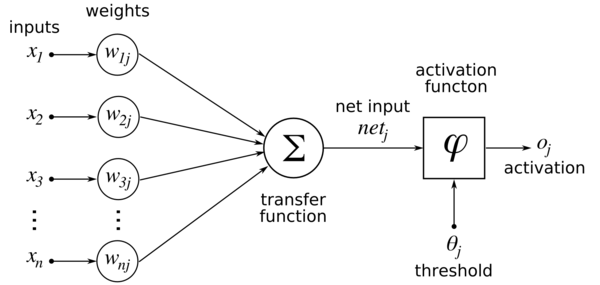
I would take two-layers neural network and would manually choose value of weights and biases such that the neural network mimics absolute value function. I have one input(x) and one output(y) and in the single hidden layer, I have two nodes. So, the neural network model becomes:
The value of output(y) then becomes:
$$ y=max({ w }_{ 1 }^{ [2] }max\left( { w }_{ 1 }^{ [1] }x+{ b }_{ 1 },0 \right) +{ w }_{ 2 }^{ [2] }max\left( { w }_{ 2 }^{ [1] }x+{ b }_{ 1 },0 \right) +{ b }_{ 2 },0) $$
I put manually the weights as:
$$ { w }_{ 1 }^{ [2] }={ w }_{ 2 }^{ [2] }=1,\quad { w }_{ 1 }^{ [1] }=1,{ w }_{ 2 }^{ [1] }=-1,\quad { b }_{ 1 }=0,{ b }_{ 2 }=0 $$
So, the equation becomes:
$$ y=max(max\left( x,0 \right) +max\left( -x,0 \right) ,0) $$
For $ x \ge 0 $, we have:
$$ y=max(max\left( x,0 \right) +max\left( -x,0 \right) ,0)\\ y=max(x,0)=x $$
And, for $x<0$, we get:
$$ y=max(max\left( x,0 \right) +max\left( -x,0 \right) ,0)\\ y=max(-x,0)\\ y=-x $$
We got the definition of the overall neural network as absolute value function. Hence, it is proved that the parameters I gave modeled the neural network as absolute value function.
Using custom parameters, I am able to model absolute value function by using the neural network. Accordingly, we can model more complex function by using the bigger neural network with appropriate parameters.
Hopefully, I gave you more intuition here about non-linearity of ReLU integrated networks.
Now, let's try to do model classification algorithm by using non-linearity property of ReLU functions. Suppose the points inside a unit circle are of one class and that outside the unit circle are of another class. Let's see if we can model the boundary using ReLU activations.
Let 0 represent the class when the point is inside the circle and 1 represent the class when the point is outside the circle. I would try to approximate the circle boundary using four straight lines which we would show being formed by a ReLU activated neural network.
The exact boundary and approximated boundary are shown below.
Now, let's try to model approximate boundary using the neural network here.
Let me remind that the points inside boundary are represented by 0 and the points outside the circle are represented by 1.
I choose the network in such a way that it approximates the boundary and the classification model.
Here, I have four nodes in the hidden layer, two inputs, x and y, and then an output classifying 0 or 1.
The output(O) can be constructed as:
$$ O=(max(x+y-1,0)+max(-x+y-1,0)+max(-x-y-1,0)+max(x-y-1))>0 $$
We would find O from x and y using the neural network now with final output layer being a relational operator.
The neural network is constructed as shown in the figure below.
This neural network constructed above does the classification of the specified problem taking the approximated boundary. The more nodes we make in the hidden layer, the more close the approximated boundary is to the exact boundary. So, to construct the complex boundary we employ the higher number of neurons. But there is always the chance of overfitting to the training set so we should build the model along with testing in the validation set.
Hopefully, I gave some intuition on non-linearity property of ReLU activations. Any feedback, suggestions, and comments are highly welcomed. I hope to bring more and more of the articles in the coming days relating to machine learning, artificial intelligence, mathematics and computer science.
Thank you.